本文旨在聊一聊目前较为有名的ai智能测试方案
引子
计算机科学之父艾伦·图灵(Alan Turing)在1950年发表了人工智能领域具有里程碑意义的论文: Computing Machinery and Intelligence, 并在里面提到了一个革命性的问题: Can machines think?, 并在其中写下了一个测试方案, 也就是我们最为熟知的图灵测试(Turing test), 然而随着ai浪潮的到来, 图灵测试是否依然有效, 成为了一个备受争议的话题。
图灵测试
图灵测试的设定通常是这样的:一个人类评审员通过与一个人类和一个机器进行对话,评审员的任务是判断哪个是机器,哪个是人类。如果评审员无法正确辨别,或者误判的概率非常高,那么机器就被认为通过了图灵测试。
这种测试的好处是其同将机器是否能拥有意识、情感或思考能力的复杂难以判断的问题巧妙的转化为了判断其是否能够成功的模仿人类, 因此很多人称其为一种模仿游戏。
图灵测试的局限
图灵测试作为一种行为上的模仿游戏, 不可避免的成为一种行为主义判断和理解事物的基准, 但其会与认知主义产生不可避免的冲突。认知主义者认为外在行为表现并不能代替更为重要的内在认知, 仅凭外在的行为表现并不能确定机器具备智能, 并进行了著名的中文房间对其进行反驳。
除此之外, 评审员数量, 评审员误判的阈值, 问题类型, 测试时间和环境, 评审员的背景与能力等都没没有准确的定论导致对图灵测试的结果产生影响, 尤其是评审员是否日常使用ai对于实验结果影响巨大。
而且图灵测试讲究的是如何模拟人类, 换句话说就是如何欺骗人类, 以此作为目标故意在问题上错答或回答不知道本身就是没有意义的, 因为人工智能存在的意义应该是如何提高生产力, 将人们从繁重的体力劳动中解放出来。
中文房间
反对图灵测试的实验中, 最有名的当属约翰·希尔勒的中文房间实验。
希尔勒设想自己被关在一个密闭的房间里,不懂中文,但手边有一本详细的规则手册。有人从窗口递进一张写有中文问题的纸条,他只需根据手册的规则将这些字符组合成合适的回答,再将答案递出。
中文房间实验突出了图灵测试的几个关键局限:
- 语法vs语义: 图灵测试的结果依赖于外在行为(语法正确的输出),而中文房间实验强调语义理解的重要性–仅仅生成正确答案并不等同于真正的理解。
- 模仿而非智能:如果机器的目标仅是模仿人类行为,那么它可能擅长伪装,但不一定具备认知能力。例如,现代大语言模型能够模拟对话,但它们的理解能力受到质疑。
- 意识和认知的缺失:希尔勒指出,即便一个系统能通过图灵测试,它依然可能没有“意识”或“认知”,因为它只是在执行规则,而不是在思考。
虽然因此赞同和反对约翰·希尔勒的大有人在, 但其确实也提供了对于机器内部认知测试的新的思考思路。
LLM
了解大语言模型(LLM)原理的都知道其本质上就是一个黑盒实验, 基于模式统计和统计预测去回答人类的问题, 其的幻觉输出本身就说明其缺乏真正的知识理解和推理能力。 因此在去年发表在nature中的ChatGPT broke the Turing test — the race is on for new ways to assess AI(链接)中虽然表明chatgpt-4成功通过了图灵测试, 但人们对其是否存在智能也是本身存在怀疑。
测试集方法
因为图灵测试在以上诸多方面具有明显的局限性, 所以人们想出了用测试集测量ai智能性的方法, 即用不同的测试集测试包含各类问题,测试其正确率并进行打分对模型进行量化。这种方法通过构建多样化的测试集,从不同角度评估AI的能力。
但这样做也依旧存在明显地缺点, 首先模型做题能力并不完全等于模型泛化能力, 其次模型在某些特定方面很强并不等于其具有通用性, 除此之外模型的训练数据也会影响其答题分数, 训练的越多的方面的答题越准确, 这些原因都让其结果难以具有代表性。
ARC-AGI测试
2019年François Chollet提出了ARC(Abstraction and Reasoning Corpus),用于评估通用人工智能的能力。ARC是一种新颖的测试方法,专注于衡量机器的抽象推理和归纳能力。
例子如图:
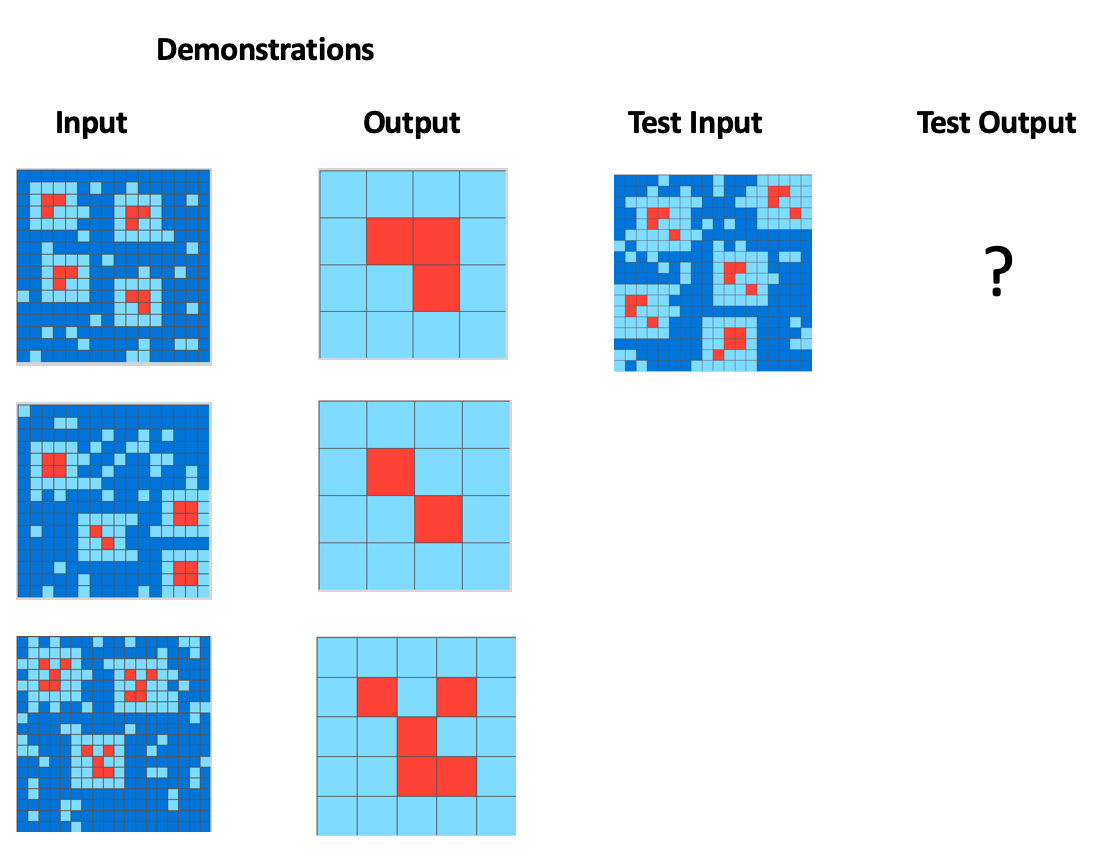 ARC-AGI Github Link
ARC-AGI Github Link
AI必须要通过前三组数据找出其应该返回与其他红色片段不同的红色片段的规律, 才能正确返回对应图片的红色片段。因为其需要AI判断图片内在抽象逻辑, 所以这种方法需要AI具有一定的泛化能力, 也因此更可以作为一个代表性测试方案用于判断此AI是否具有智能。
总结
人工智能的测试从早期的图灵测试,到现代测试集评估,再到ARC-AGI测试方法,都在不断探索如何科学衡量机器智能的真正能力。在未来的智能评估方法中,更需要兼顾模型的泛化能力、认知深度和适应性,以便真正揭示AI在复杂环境中的潜力, 推动其朝着真正通用智能的方向迈进。