本文主要介绍如何通过IDEA完成项目导入与jar包的上传并在hadoop上完成MapReduce任务的执行(需要已经写好的java项目和对应的jar包)
引言
经过了前面hadoop集群的启动, 我们可以开始编写MapReduce任务了, 本文主要介绍如何通过IDEA完成项目与包的导入, 将jar包的上传到linux, 并在hadoop上完成MapReduce任务的执行
导入项目module和所需jar包
导入项目module
打开IDEA, 如图所示:
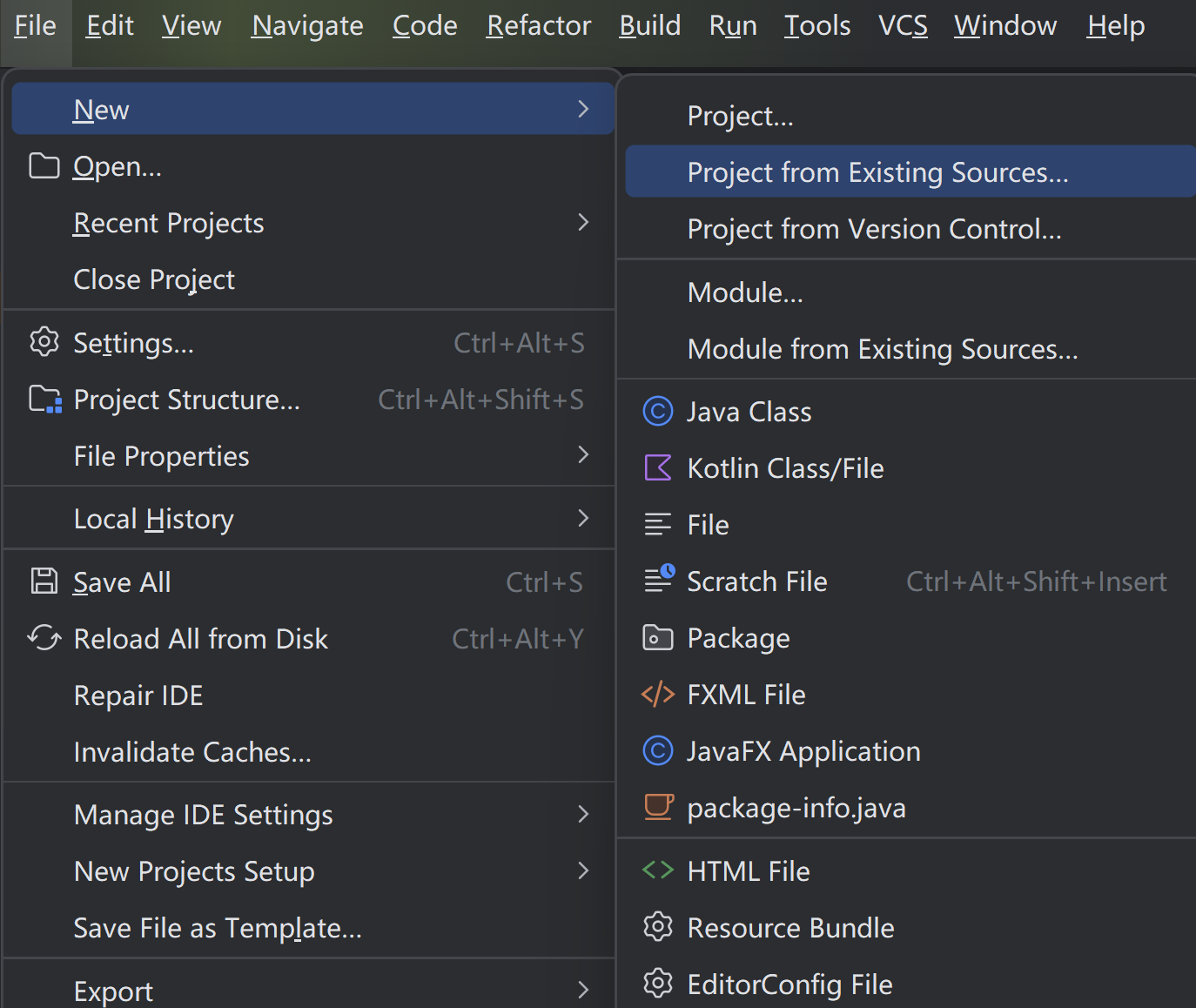 点击
点击File -> New -> Project from Existing Sources, 选择已经写好的java项目所在的目录, 一路下一步, 将jdk版本选择为1.8(java 8), 重新写入.iml和.idea文件, 最后点击Finish
导入所需jar包
点击File -> Project Structure, 如图所示:
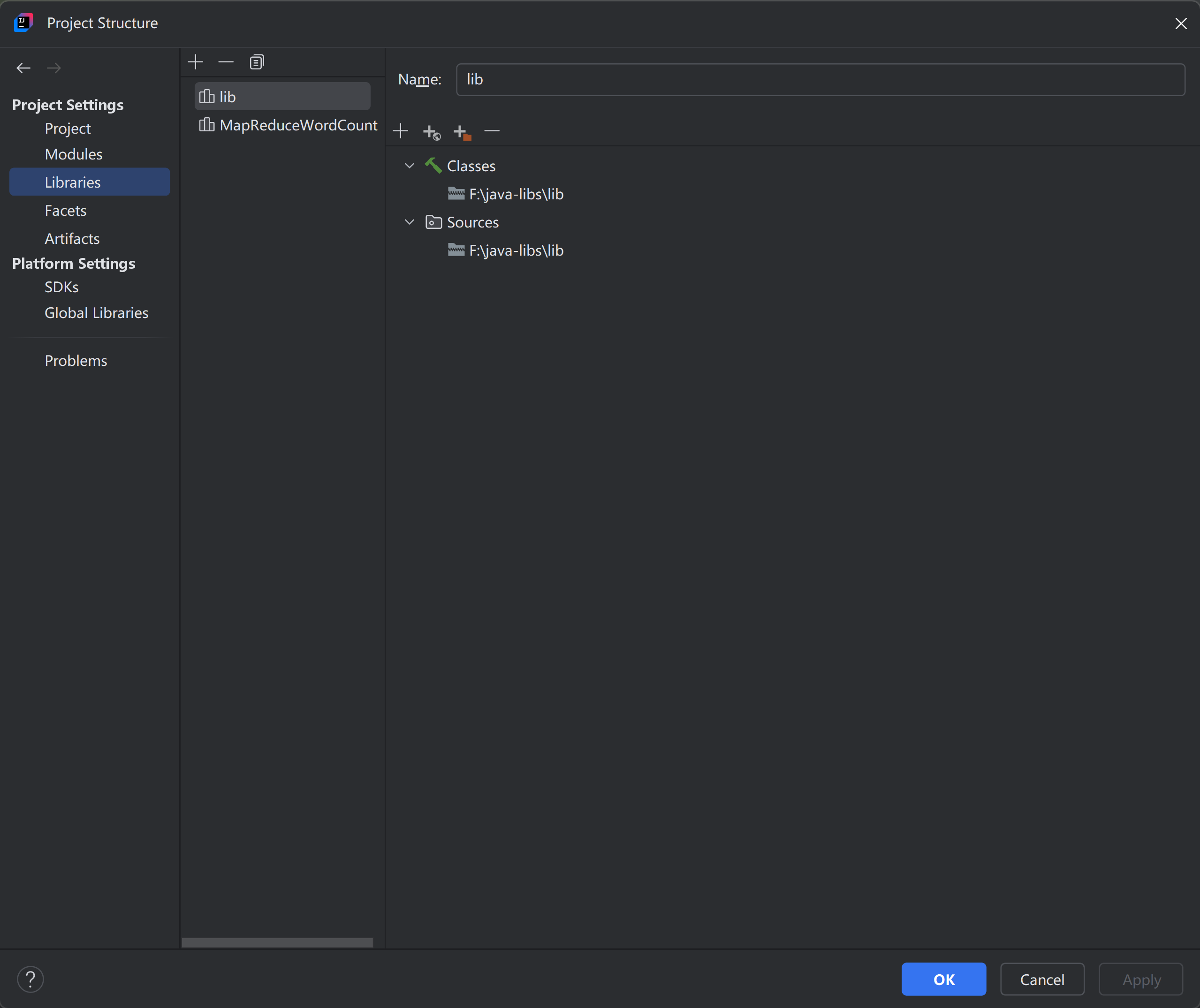 点击
点击Libraries -> + -> Java, 选择所需的jar包, 点击OK即可
将上传的jar包导入到module
点击File -> Project Structure-> Modules -> Dependencies, 点击+ -> Library, 选择之前上传的jar包, 点击OK即可
将项目打成jar包
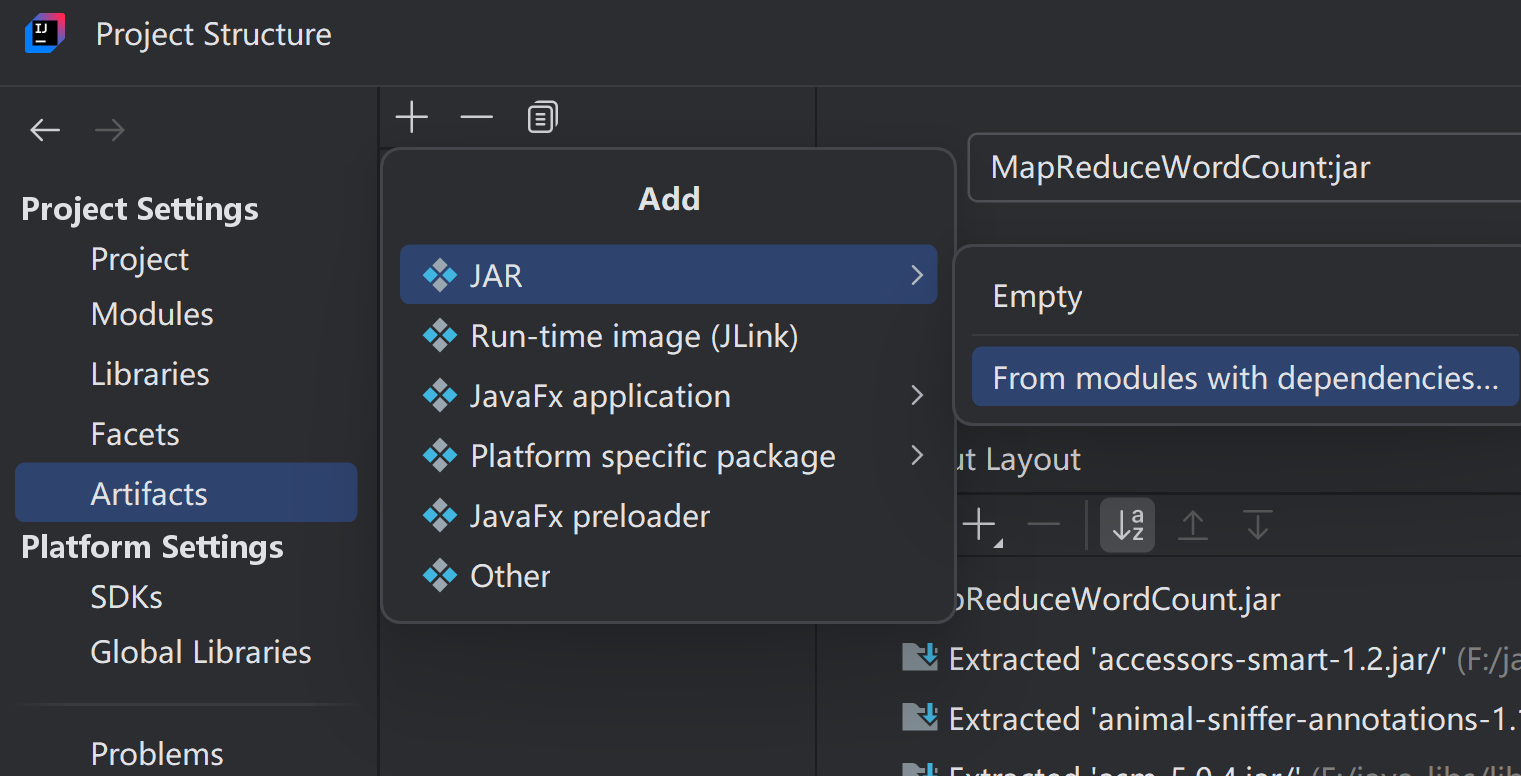 点击
点击File -> Project Structure-> Artifacts, 点击+ -> JAR -> From modules with dependencies, 选择之前导入的Module和Main Class, 点击OK即可, 然后点击Apply -> OK
然后在out文件目录中的artifacts目录下就会有一个jar包, 我们将这个jar包可以通过Xftp上传到linux
如何执行该jar包
先将jar包上传到linux, 然后在linux上执行以下命令:
1
hadoop jar /path/to/jarfile.jar /path/to/input/file /path/to/output
- 注 : /path/to/jarfile.jar为jar包的路径, /path/to/input/file为输入文件, /path/to/output为输出文件的路径, 根据需要进行修改
查看输出结果
打开mapreduce webui, 可以看到mapreduce的历史执行记录, 可以确定任务是否执行成功, 以及执行时间等信息
FAQ
/Path/to/input/file文件为什么没有被读取
/input/file/file 和 /path/to/output 都是hdfs上的路径, 所以需要先将文件上传到hdfs上, 然后再执行命令, 命令如下:
1
hadoop fs -put /path/to/local/file path/to/input/file
- 注 : /path/to/local/file为本地文件的路径, /path/to/input/file为hdfs上的路径, 根据需要进行修改, 如果不存在path/to/input/file目录, 则需要先创建目录, 命令如下:
1
hadoop fs -mkdir path/to/input/file
如果jar包没有生成或以外被删除了, 如何解决
点击Build -> Build Artifacts -> Rebuild 即可生成jar包